Acceleration of Shallow Water Simulations on FPGAs
- Principal Investigators:
- Prof. Dr. Christian Plessl
- Project Manager:
- Dr. Tobias Kenter
- HPC Platform used:
- PC2: Noctua 1, in particular Bittware 520N cards with Stratix 10 FPGAs
- Project ID:
- hpc-lco-kenter
- Date published:
- Researchers:
- Prof. Dr. Vadym Aizinger, M.Sc. Sara Faghih-Naini, M.Sc. Jennifer Faj
- Introduction:
- Shallow water simulations are important for climate models, flood or tsunami predictions and other applications. Performing such simulations on unstructured meshes with the Discontinuous Galerkin method is numerically attractive, but a performance challenge on conventional architectures. With a customized dataflow architecture implemented on FPGAs, we have improved performance and power efficiency on a single FPGA and achieved promising initial results when scaling to multiple FPGAs via direct FPGA-to-FPGA interconnects.
- Body:
-
Shallow water simulations are an active research area, both under numerical and algorithmic aspects, and from a performance engineering perspective. In particular in the context of climate simulations, where long simulation time scales need to be achieved, and in the context of tsunami or flood predictions, where accurate models with high spatial resolutions need to be evaluated quickly, use of accelerator technologies can play a crucial role to match performance demands.
In this project, we investigate the suitability of FPGAs and their dataflow computation paradigm for a research code implementing the Discontinuous Galerkin (DG) method and using unstructured grids. The irregular memory accesses and dependencies on neighbouring elements that are defined by the mesh topology let unstructured grids pose a performance challenge for hardware architectures focusing on regular data parallelism. Additionally, small trip counts of inner loops of the DG kernels like 3, 6 and 9 depending on polynomial orders of the discretization are ill fitting for the vector units of current CPUs. FPGAs, with their dataflow execution paradigm that combines instruction and task level parallelism in deep pipelines with customizable data level parallelism and a flexible on-chip memory hierarchy, are thus conceptually a promising architecture alternative.
In a first step targeting single-node acceleration, after functionally offloading the computational kernels via OpenCL, we incrementally refactored the structure of the code in order to improve the design generated via high-level-synthesis. While initial improvements to loop pipelining were straight forward, they were not sufficient to reach competitive performance. Discussions between performance engineers and method experts allowed to adjust the algorithmic structure to create a dataflow architecture that overlaps all computation phases in time. Finally, the on-chip memory resources were partitioned such that for the entire computation pipeline, stall-free access for every local load and store operation is guaranteed at compile-time.
With this approach, asymptotically, in every clock cycle an entire grid element can be processed with up to 4256 floating point operations per cycle, depending on the polynomial order of the spatial discretization used. This allows to achieve a speedup of up to 144x over a single-core CPU reference, which even in case of perfect scaling on the CPU, which we currently don’t see, would translate to more than 3.5x speedup over the dual socket Intel Xeon Gold "Skylake" 6148 CPUs in the Noctua 1 system. Remarkably, the Intel Stratix 10 FPGAs manufactured with the same 14nm process achieve this performance with at most 80W power consumption measured for this design. [1]
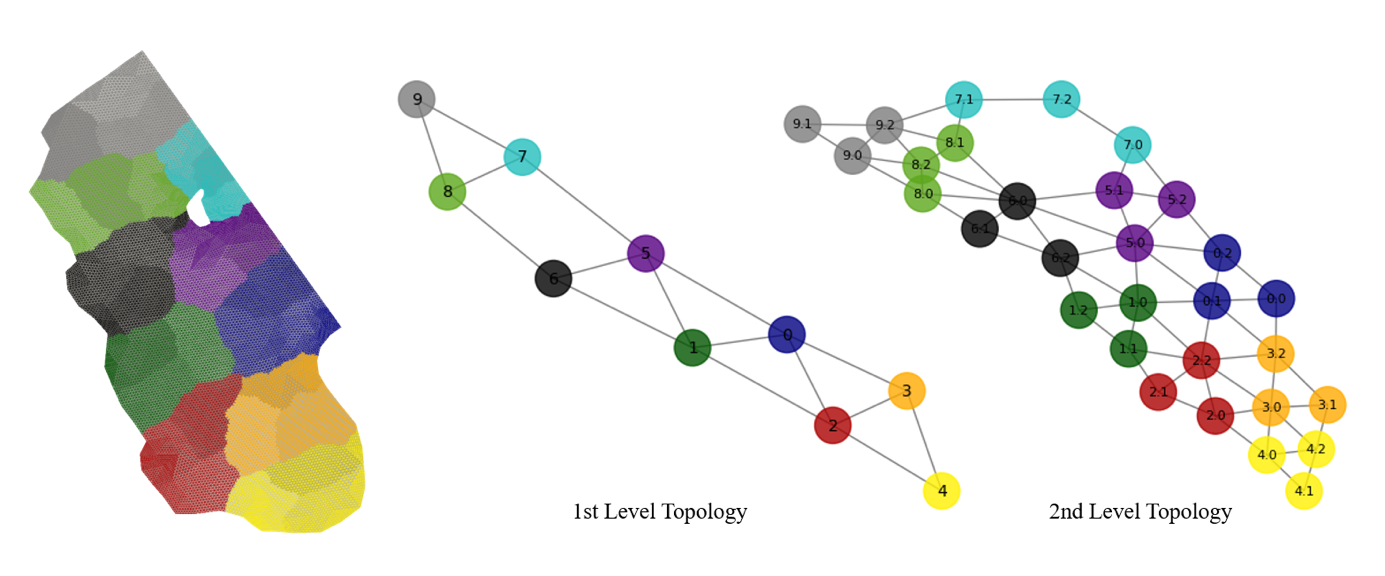
Ongoing research targets further performance improvements, generalization of the approach, and particularly strong and weak scaling over multiple FPGAs via direct FPGA-to-FPGA interconnects. Using spatial decomposition with halo exchange, the transfer latency of the serial streaming interfaces between FPGAs can mostly overlap with the local pipeline latency. Figure 1. (pipeline.png) illustrates this for an extreme case with only around 430 mesh elements per partition, where the aggregate pipeline and communication latencies lead to around 3µs execution time per full time step and an occupancy of around 43% for the entire FPGA pipeline. More suitable partition sizes allow for higher occupancy and an initial hierarchical design distributing 30 mesh partitions over a total of 15 FPGAs (Figure 2, hierarchical.png) demonstrated around 2 TFLOPs of sustained performance at around 6µs per full time step for 27136 mesh elements. We expect that additional design improvements and emerging FPGA features like high-bandwidth memory (HBM2) and collective communication features can improve the scalability of this approach further.
[1] Tobias Kenter, Adesh Shambhu, Sara Faghih-Naini, and Vadym Aizinger. Algorithm-Hardware Co-design of a Discontinuous Galerkin Shallow-Water Model for a Dataflow Architecture on FPGA. Proc. Platform for Advanced Scientific Computing Conf. (PASC), 2021. https://doi.org/10.1145/3468267.3470617
- Institute / Institutes:
- Paderborn Center for Parallel Computing
- Affiliation:
- Paderborn University, University of Bayreuth
- Image:
-